ChatGPT vs Claude vs DeepSeek: Project Estimate Automation


When building software, project requirements often change, sometimes slightly, sometimes drastically. Each change, even a small one, can affect the estimated effort and overall timeline. For software agencies, this creates a recurring challenge: how do we quickly and reliably recalculate project estimates when clients update or restructure their specifications? If you want to automate project estimates with AI in your own stack, build an AI-powered estimation workflow.
Traditionally, project managers or tech leads handle this task manually. They compare documents, track user stories, adjust timelines, and communicate the impact to stakeholders. This takes time and leaves room for inconsistencies, especially in fast-paced environments or when dealing with large documents.
With the rise of large language models (LLMs), there’s an opportunity to rethink this process. Could AI automatically and with acceptable accuracy handle the task of understanding specification changes and calculating the required effort?
In this experiment, we tested that idea. We wanted to know:
- Can LLMs compare two versions of a technical spec and detect all important changes?
- Can they estimate how much extra work is involved based on the updated requirements?
- Can they format the result clearly enough to be used by engineers, project managers, or clients?
Approach
To test how well large language models can assist with changing project specifications, we designed a controlled experiment using a real-world scenario: a frontend redesign task. This allowed us to simulate how a team might update project estimates after a change in client requirements.
We prepared two specification documents:
- Initial version: a user story with clear frontend tasks, including a scope breakdown and baseline estimates.
- Updated version: the same story with slight but realistic changes, some elements were added, removed, or reworded to reflect typical client feedback during development.
Our goal was to compare these two versions and calculate the difference in effort.
We tested three LLMs:
- ChatGPT 4 (OpenAI)
- Claude 3 Opus (Anthropic)
- DeepSeek-V2 (Open-source)
Each model received the same structured prompt, asking it to:
- Identify and summarize all relevant changes between the two documents.
- Estimate the additional time required (in hours).
- Justify the estimate clearly, using bullet points or tables.
To keep the evaluation fair and reproducible, we used the same input format and prompt for each model, and recorded their outputs without any manual tweaks. The prompts were carefully engineered to be clear, structured, and consistent.
We then compared the results across these dimensions:
- Accuracy of detected changes
- Clarity of output and formatting
- Plausibility of time estimates
- Efficiency in completing the task
- Suitability for real-world agency workflows
This structured approach allowed us to test the strengths and weaknesses of each model and evaluate their practical value in agency use cases.
What We Tested
The purpose of this experiment was to evaluate how well leading LLMs can support real-world change estimation in software projects.
In most projects, requirements change, sometimes slightly, sometimes significantly. When that happens, teams need to quickly:
- Understand what changed in the specification
- Recalculate the effort needed to complete the new version
- Communicate those changes clearly to clients and team members
This is usually a manual task, done by a senior developer, project manager, or tech lead. We wanted to know if LLMs could handle this kind of estimation work with enough accuracy and clarity to be used in a professional environment.
We tested the models on these capabilities:
- Change detection: Can the model correctly identify and summarize all changes between two versions of the same project spec?
- Estimation accuracy: Can the model give a realistic time estimate (in hours) based on the changes?
- Explanation clarity: Does the model clearly explain why a change impacts effort? Are the justifications logical?
- Formatting and structure: Is the output well-structured and easy to use in real workflows (e.g., bullet points, tables, labels)?
- Sensitivity to small edits: Can the model notice and properly evaluate small but important edits like renaming buttons or changing layout rules?
The goal wasn’t just to find the “best” model, but to understand how usable these models are in agency or SaaS environments where accurate estimates and clear communication are key to maintaining client trust.
We tested three leading LLMs: OpenAI’s GPT-4o, Anthropic’s Claude 3.7, and DeepSeek V3. Each model was given the same prompt: a “before” and “after” version of a project specification, and a request to identify the changes and estimate the required effort.
Here’s a summary of the results:
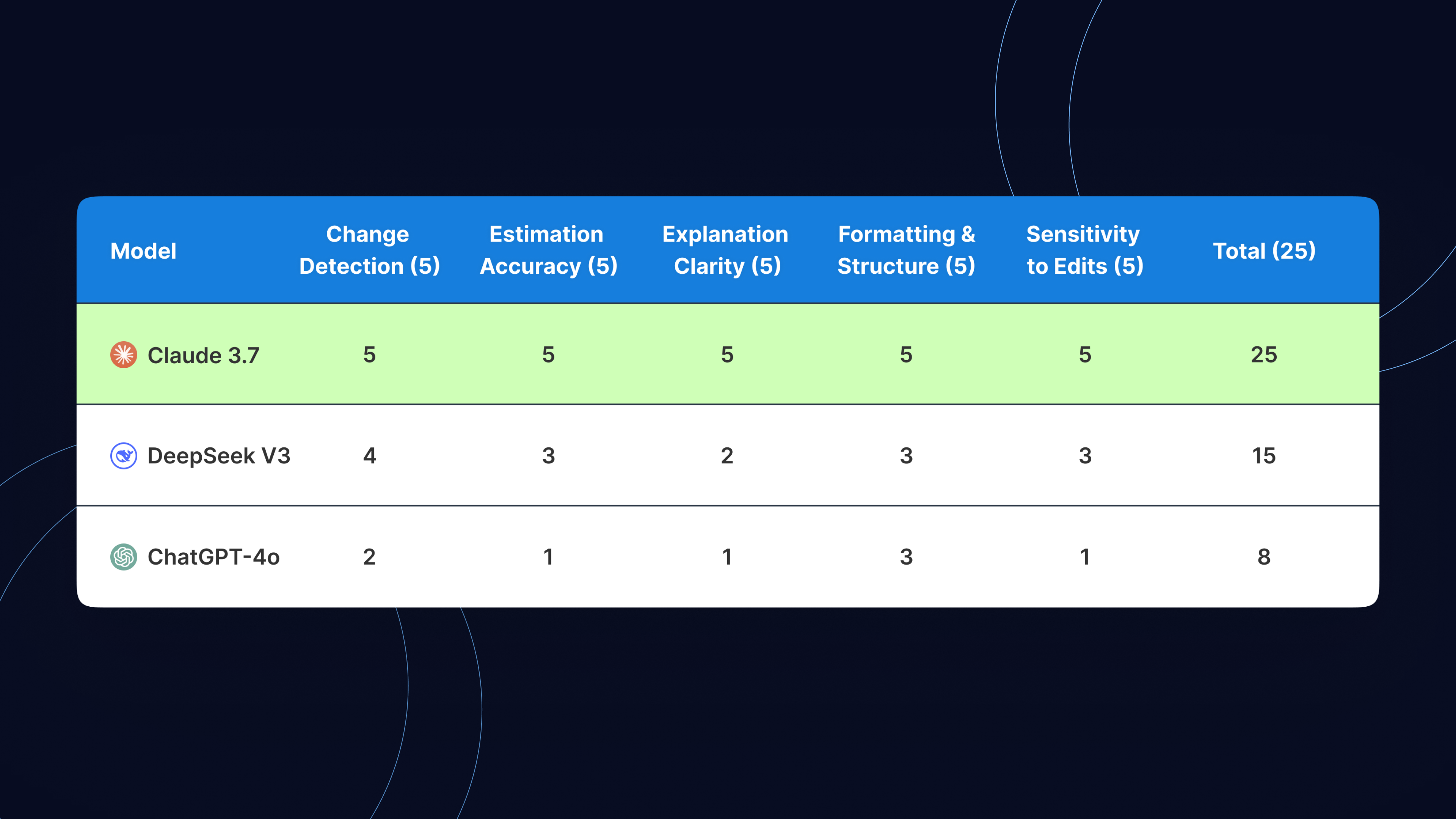
Key Takeaways:
- Claude 3.7 delivered near-perfect results across all tested areas. It correctly identified all meaningful spec changes, provided accurate and well-justified time estimates, and formatted the response clearly for use in development workflows.
- DeepSeek V3, while open-source, showed potential but lacked depth. It missed subtle edits and offered generic reasoning, which may limit its use for detailed change tracking or spec reviews.
- ChatGPT-4o struggled the most. Despite being a premium tool, it failed to notice most changes and provided surface-level justifications that lacked technical grounding. It’s currently not reliable for tasks requiring high context awareness or structured estimates.
Example Comparison
Claude 3.7 provides full reasoning and estimates aligned with development practices. DeepSeek V3 gives only rough numbers, while ChatGPT-4o fails to recognize the backend impact and provides little actionable output.
Conclusions
Using LLMs for change estimation in software projects shows real potential, but only when used with the right expectations.
First, LLMs can speed up the estimation process, especially in cases where developers need to quickly assess the scope of updates or compare project specs. In our testing, only Claude demonstrated this level of reliability. It accurately detected edits, explained their impact on effort, and used formatting that could plug into real development workflows.
Second, the quality varies across models. While Claude performed flawlessly across all evaluation criteria, DeepSeek missed small but important changes and gave vague estimates. ChatGPT, surprisingly, was the weakest performer. It failed to recognize many of the edits and produced explanations that lacked context and structure, falling short of even a junior analyst’s level of performance.
Third, LLMs should not replace developers, but they can support them. A senior engineer reviewing AI-generated estimates can save time while keeping full control over decision-making. This hybrid workflow (AI-generated first draft + human validation) is likely the most practical use case.
Lastly, teams need clear prompts, structured templates, and quality control processes if they want to integrate LLMs into their estimation pipelines. Otherwise, there’s a risk of bad assumptions or miscommunication with clients and stakeholders.

In short: LLMs are not perfect, but they are ready to help, especially when guided by experienced professionals. For companies considering automation in project scoping, choosing the right model and keeping humans in the loop is critical.
Who Can Benefit from This
This research and approach are especially useful for several groups working in software development, product management, and technical consulting.
1. CTOs and Engineering Managers
If you lead a technical team, this approach can help you accelerate early-stage project planning. By using LLMs to pre-analyze requirement changes and estimate scope, your senior engineers can focus on validation and edge cases rather than starting from scratch.
2. Product Owners and Business Analysts
For those managing backlog grooming or preparing for sprint planning, LLM-generated estimation drafts can give a quick sense of complexity. This helps in setting more realistic deadlines and communicating early with stakeholders about potential risks.
3. Delivery Teams in Outsourcing and Agencies
Agencies often need to review long requirement documents and send back effort estimates fast. LLMs can help create first-draft estimates, highlight scope changes between versions, and prepare client-facing documentation, all of which reduce turnaround time and improve consistency.
4. Pre-Sales Engineers and Proposal Writers
During the bidding phase, this method can assist in comparing incoming requirements to previous projects and speed up proposal drafting. With an AI-generated change analysis, pre-sales teams can prepare questions, identify red flags, and communicate more clearly with prospects.
5. AI Researchers and Tool Builders
Those designing tools that combine LLMs with project management or specification analysis will benefit from the insights here. Our real-world benchmarks offer a clear direction for where models excel, where they struggle, and how structured prompts can improve accuracy.
In short, if your role involves translating client requirements into software tasks or planning engineering effort, this method is worth exploring. It won’t replace deep experience, but it can remove a lot of the repetitive work and help you move faster with confidence.
Conclusion
Large Language Models like ChatGPT, Claude, and DeepSeek show real promise in helping teams analyze changing software requirements and estimate the impact on development effort. While their responses are not always perfect, they can successfully identify modified user stories, suggest relevant changes, and even propose updated task lists with solid reasoning, especially when guided by structured prompts.
In our tests, we saw that LLMs can reduce the time spent on initial estimation drafts and help teams spot critical changes faster. They perform best when combined with human oversight and used as a tool to enhance, not replace, professional judgment.
For organizations that frequently deal with evolving specs, fast-paced discovery phases, or multi-round estimations, this approach adds value. It creates room for better planning, faster alignment between stakeholders, and ultimately, fewer surprises during implementation.
Frequently asked questions
- Which AI model is best for software project estimation in 2026?
- Claude tends to be the most consistent on structured spec parsing and effort estimation. ChatGPT is faster on iteration. DeepSeek is the cheapest at scale. The right choice depends on volume and accuracy tolerance.
- Can AI replace a senior engineer for project estimates?
- No, but it can cut the time a senior engineer spends from hours to minutes. The model produces the first estimate; the engineer validates assumptions and edge cases. That is the realistic 2026 workflow.
- How accurate are AI-generated project estimates?
- Within 15 to 25 percent of actual effort on well-scoped projects when the model has access to similar past projects. Accuracy drops fast on novel domains or unclear requirements.
- What information does an AI model need to estimate a project?
- Tech stack, scope per feature, integration points, existing constraints, and ideally 2 to 3 past projects of similar size for calibration.
- How much does AI-powered project estimation cost?
- Roughly 0.10 to 1.00 USD per estimate at API rates in 2026. The savings against a senior engineer's hourly rate are immediate even at the high end.
Build the AI Estimation Workflow That Actually Ships
Valletta Software builds production AI workflows on Claude, ChatGPT, and DeepSeek for software estimation, support automation, and decision support. Vetted engineers, EU-based.